Data flow testing is a white box software testing technique in which test cases are designed based on the definition and usage of the variable within the code i.e. testing of definition-use pair (du-pairs). Data flow testing must not be misunderstood with data flow diagrams, as they don’t have any connection.
Before talking about the data flow testing technique in greater detail, let’s quickly run through different phases for a data item in its normal life cycle as well as understand the types of du-pairs.
Phases of Data Item during Normal Life Cycle: Generally a data item or variable passes through four phases during its normal life cycle, that are;
Declaration phase: During this phase a space is reserved in the memory for the variable value. Some programming languages permit variables to be used before they are declared; This type of first usage is treated as an implicit declaration.
2) Definition phase: During this phase a value is assigned to the variable.
3) Use phase: During this phase the value of the variable is used.
4) Deletion phase: During this phase the memory reserved for the value of the variable is freed for use elsewhere.
Analysis of “Definition” and “Use” of Variables: Problematic cases in the data flow that causes defects in our program are;
1) A variable is used before it is declared.
2) A variable is used before it is defined.
3) A variable is defined twice before it is used.
4) A variable is used after it is cleared of the memory or after deletion.
In the context of a flow graph, a “definition” occurs at a node. Thus we can make two statements like;
Statement-1: That there is a “definition” of variable “v” in a node “n” if and only if the value of variable “v” is bounded in one of the statements in “n”.
Statement-2: That there is a “use” occurrence of a variable “v” if and only if the value of variable “v” is accessed.
Classification of Reference of Variables: Generally variables can be referenced in two ways.
1) Computation Data Use (c-use): Here the variable is not used in a condition. For example a variable “v” is used in defining the value of another variable or is used as an output value, then it is a “c-use” of variable “v” in node “n”.
2) Predicate Data Use (p-use): Here the variable is associated with the decision outcome of the predicate portion of a decision statement. For example a variable is used to determine the True/False value of a predicate, and a predicate associates with an edge “e”, then this is a “p-use” of variable “v” in the edge “e”.
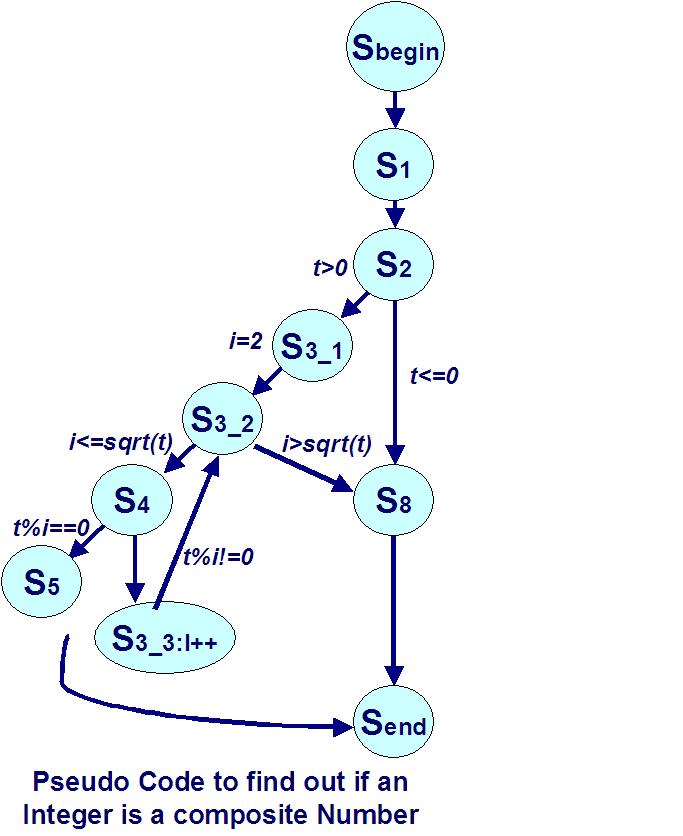
Consider the following pseudocode describing the internal structure of the program to determine whether an integer is a composite number. All the decision nodes here have two outgoing edges. Statement “S1” has been included in the diagram because it is an initial statement for variable “t”, which will be used later.
S1 Boolean Composite (integer t)
S2 if (t > 0) S3 for (i=2; i <=sqrt(t); i++) S4 if (t%i==0) S5 return true; >
S6 >
S7 >
S8 return false;
Interpretation:
At node “S3_1”, there is a definition for variable “I”. For edges (S3_2, S4) and (S3_2, S8), there are “p-uses” for variables “I” and “t”.
If a path “P” =(p1, p2, �, pk−1, pk), where there is a “definition” of “v” in “p1” and either “pk” has a “c-use” of variable “v” or (pk−1, pk) has a “p-use” of variable “v”, then “P” is a “definition-use path” (du-path) with respect to variable “v”.
Given a “du-path” with respect to variable “v”, if one of the intermediate nodes also defines “v”, then, the definition at node “p1” will be rewritten, and has no effect on the “c-use” at node “pk” or “p-use” at edge (pk−1, pk).
To distinguish this scenario from other scenarios, a definition-clear path is defined. A P = (p1, p2, �, pk−1, pk) is a “definition – clear path” w.r.t variable “v”, if and only if “P” is a “du-path” with respect to variable “v”, and in addition none of the intermediate nodes, p2, �, pk−1 have definitions of variable “v”.
For illustration of the two types of data uses like “p-use” and “c-use”, refer following piece of code;
(10) Read A;
(11) Read B;
(12) if A = 983 then
(13) Write �Genius�;
(14) endif;
(15) If A < B then
(16) A = B;
(17) else
(18) A = 0;
(19) endif;
(20) Write A;
Example of p-use of variable B: Line 15
Example of c-use of variable B: Line 16
Examples of du-pairs: (Line 10 & 13), (11 & 16)
A sub-path in the flow is defined to go from a point where a variable is “defined”, to a point where it is “referenced”, that is, where it is “used” – whatever kind of usage it is. Such a sub-path is called a “definition-use pair” or “du-pair”. The pair is made up of a “definition” of a variable and a “use” of the variable.
Based upon two kinds of usage, we have three types of du-pairs like;
1) Definition to c-use
2) Definition to p-use
3) Definition to use (either c or p)
Types of coverage for Data Flow Testing: The coverage items for the data flow testing technique are the “control flow sub paths” and “full paths” through the code. Different types of coverage for data flow testing are tabulated as under.
| Abb. | Description | Definition |
| d | All-definition coverage | %age of covered sub-paths from each variable definition to some use of that definition |
| duc | All data definition c-use coverage | %age of covered sub-paths from each variable definition to every c-use of that definition |
| dup | All data definition p-use coverage | %age of covered sub-paths from each variable definition to every p-use of that definition |
| u | All use coverage | %age of covered sub-paths from each variable definition to every use of that definition (Irrespective of the type) |
| du-path | All definition use path coverage | %age of covered “simple sub-path” from each variable definition to every use of that definition |
Process of Test Case Design using Data Flow Test Technique: While designing test cases with the data flow software testing technique, we concentrate on one component and for that component we carryout the following activities;
a) Number the lines, if not numbered already
b) List the variables
c) List each occurrence of each variable and assign a category (definition, p-use, or c-use)
d) Identify the du-pairs and their type (c-use or p-use)
e) Identify all the sub-paths that satisfy the pair
f) Derive test cases that satisfy the sub-paths
When the final test procedures are designed from the test cases, they will of course follow a path in the control flow through the code.
Data flow based criteria for test case creation: Based on the notations of definition, use, c-use, p-use, du-paths, and definition-clear paths, a set of data-flow-based criteria can be used to guide the test-case generation.
When testing a program, determining which criterion to choose is all about the balance of the cost and defect-detecting ability. Following figure describes a typical hierarchy of different test-adequacy criteria.
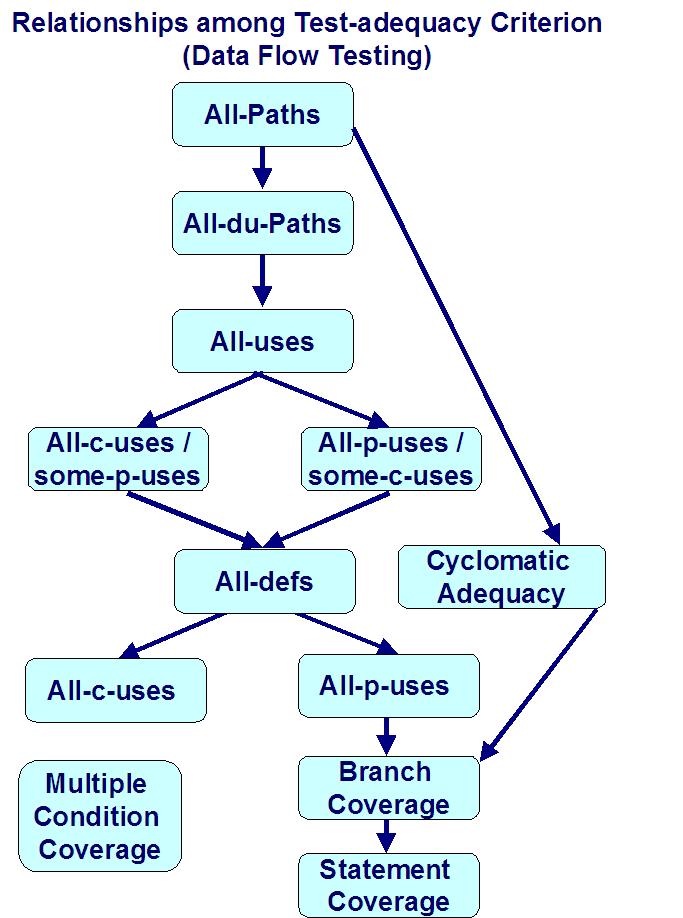
Criteria 1: A test suite “T” satisfies the “all definitions” criterion if and only if for every variable “v”, “T” has “definition – clear paths” from every node that has a definition of “v” to either a node that has a “c-use” of “v” or to an edge that has a “p-use” of “v”.
Criteria 2: A test suite “T” satisfies criterion of “all uses” if and only if for each & every variable “v”, “T” consists of “definition – clear paths” from every node that has a definition of “v” to all nodes that have “c-uses” of “v” and to all edges that have “p-uses” of “v”.
Because uses are further classified into “c-uses” and “p-uses”, the all-use criterion can be further classified into four subcategories with different potential.
Criteria 3: A test suite “T” satisfies all “c-uses” or some of the “p-uses” criterion if and only if for each & every variable “v”, “T” contains “definition clear paths” from every node that has a definition of “v” for every “c-use” of “v” and if any definition does not have any “c-uses”, then the “definition clear path” which reaches a “p-use” of “v” needs to be included in “T”.
Criteria 4: On the contrary, a test suite “T” satisfies the all “p-uses” or some of the “c-uses” criterion if and only if for each & every variable “v”, “T” contains “definition clear paths” from every node that has a definition of “v” for every “p-use” of “v”, and when a definition does not have any “p-uses”, then a “definition clear path” which reaches a “c-use” of “v” needs to be included in “T”.
For remaining two criterion, “all-c-use” and “all-p-use”, we just ignore the cases where there are no feasible “definition-clear-path” scenarios.
For the “all-use” criteria, all definition and use pairs are tested, but there can be more then one path between the “definition” and the “use” of a variable. Therefore, a more stronger criterion � “all-du-path” criterion needs to be considered.
Criteria 5: A test suite “T” satisfies the “all-du-path” criterion if and only if for each & every variable “v”, “T” contains all possible “definition clear paths” out of every defining node of “v” to each & every usage of “v”. The “all-du-path” criterion has similar issues to those path-based approaches and a number of feasible paths.
Similar process can be adopted to obtain a limited-number of “definition-clear path” in this case as well.
Problematic issues with Data Flow Testing: There are a few pitfalls here that we need to be cautious.
1) When we use array variables or pointer variables in the program, it is a bit difficult to conduct precise data-flow analysis. Data items or variables may be composed of many single variables.
For instance, in the case of arrays, which are ordered sequences of individual data items; If we ignore the constituents of composite variables like arrays and treat them as one data item, we greatly reduce the effectiveness of data flow testing. Testing tools will typically respond to an array or record it as a single data item rather than as a composite item with many constituents.
Similar issues arise for inter-procedure also.
2) Sometimes static analysis tools report a large number of anomalies that are not in fact caused by anything being wrong. These “false alarms” are liable to hide the real problems in the wake of large number of alarms.
3) Cost of conducting data-flow testing is quite higher compared to another white box testing technique of path testing.